ここ一ヶ月ほど、Cursorを使って、自分用や身近な用途の小さなツールをいくつかつくってきた。いずれもサーバーを借りたり公開サイトに上げたりせず、手元のPCでHTMLをブラウザで開くか、あるいはビルドした静的ファイルを開くだけで動く。この記事では、そうした「ローカルで動くアプリ」が自分の中でどういう位置にいるのかを、つくりながら考えたことをまとめておきたい。
「ローカルで動くHTML」とは何か
まず用語の話から。自分が「ローカルのHTMLで動くやつ」と言っているものは、技術的には次のような性格を持っている。
- サーバーを立てなくてもよい(あるいは、立てるとしても自分のマシン上の開発用サーバーだけ)
- 処理はブラウザのなかで完結する(データの送受信を外部APIに依存しないか、依存する場合もローカルでプロキシを立てる)
- 配布するときはHTMLとJSとCSS(と必要ならビルド済みの一式)を渡せばよい
業界では「静的ウェブアプリ(static web application)」や「クライアントサイドのみのアプリ(client-side only application)」といった言い方がされる。要するに、サーバー側のプログラムに頼らず、ブラウザが読み込んだファイルだけで動くもの、である。
ただし「静的」という語は、中身が固定のページだけという意味ではなく、JavaScriptでインタラクティブに動くものでも、サーバーに処理を送っていなければ静的配信の枠に入る。自分がつくったものの多くは、ファイル選択やドラッグ&ドロップでデータを取り込み、ブラウザ内で変換や計算をして、結果をダウンロードさせる形だ。
三つのツールの概要
Cursorでつくったものを、時系列に近い順で挙げる。
1. PPTX → Markdown
PowerPoint の `.pptx` を、ブラウザ内だけで Markdown に変換するツールである。`.pptx` はZIPアーカイブなので、ブラウザ上で解凍し、`ppt/slides/` 配下のXMLなどを解析して、テキストと画像を取り出す。
`index.html` と `app.js`、`style.css` の三つで構成され、サーバーも Python も Node も不要で、`file://` で開ける。出力は「1本のMarkdown+画像フォルダ」か「スライドごとのmd+画像」を選べ、Obsidian でスライドノートを管理しやすい形でZIPダウンロードできる。スピーカーノートの抽出や、Chart・Table・SmartArt には未対応である旨の警告表示にも対応している。
授業や勉強会のスライドを、そのままMarkdownで残したいという需要からつくった。
2. ほしいものリスト 予算割当(book-budget-app)
Amazon の「ほしいものリスト」から書籍候補を読み込み、複数の予算(例:科研費の品目別)に、余りが最小になるように本を割り当てるツールである。
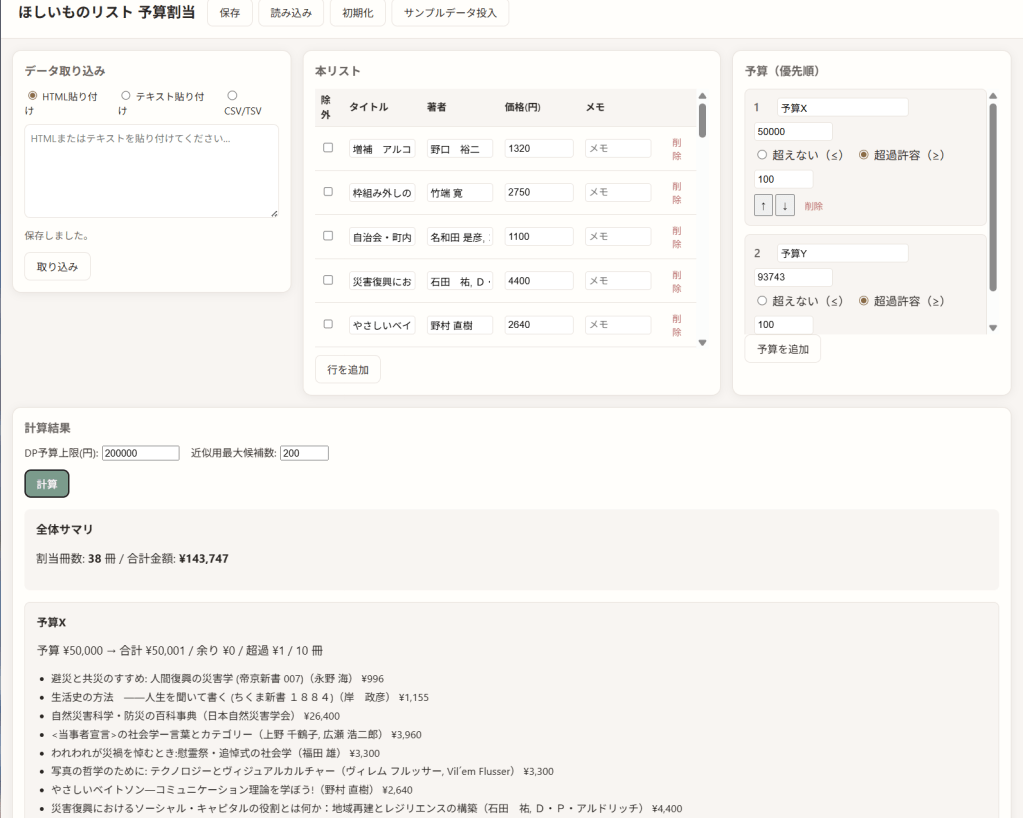
データの取り込みは、ほしいものリストのHTMLや「リストを印刷する」で出したテキスト、あるいは CSV/TSV の貼り付けに対応している。予算ごとに「超えない(≤)」か「超過許容(≥)」を選べ、優先順位をつけてから計算する。中身は動的計画法(DP)と、予算が大きいときの近似(貪欲+局所探索)である。結果は LocalStorage に保存され、外部には一切送信しない。予算ごとのリストはcsvで出力可能であり,事務局への申請も楽ちんである。
技術的には TypeScript + Vite で、`npm run build` で `dist/` に静的ファイルが出力される。`dist/index.html` をブラウザで開けばそのまま動く。
「複数予算にどう振り分けるか」を手作業でやるのがつらくなり、Cursor に問題を説明しながら一緒に組み立てた。
3. 掘り起こされるアーカイブ(shinsai-archive-search-app)
国立国会図書館の「東日本大震災アーカイブ(ひなぎく)」の API(SRU)を使った検索インターフェースである。こちらは意図的に「ずれた検索」をする仕様になっている。画面上では期間・場所・キーワードを入力して検索しているように見えるが、実際には入力条件をわずかに変えた条件でAPIを叩く。したがって、正確な情報検索のためのツールではなく、「探していたはずのものとは違うが、同じアーカイブにあった記録」を引き出すためのもの、とREADMEに書いた。また,検索結果画面が下にスクロールすればするほど,検索結果がクリアに見えやすくなる仕掛けを施した。
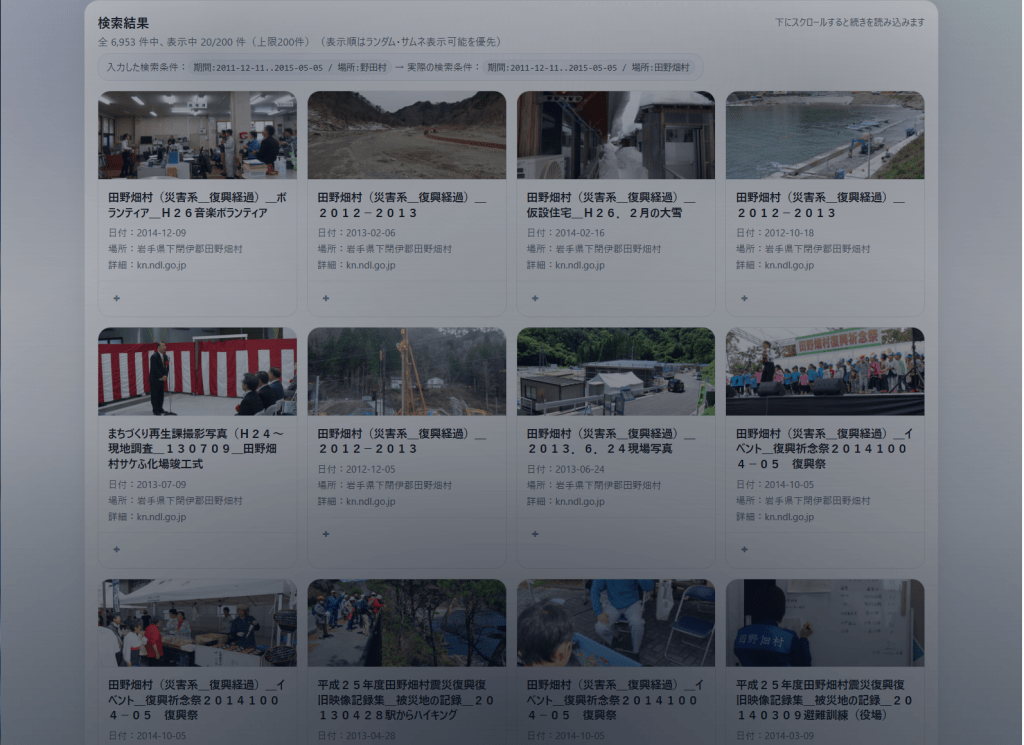
構成は、Node.js(Express)のローカルプロキシ(CORS 回避のためひなぎくAPIへ中継)と、Vite でビルドしたフロントエンド(`web/`)に分かれている。つまり、動かすときは `npm run dev`や `npm start`でローカルにサーバーを立てる必要がある点で、上の二つとは性質が異なる。それでも、サーバーは自分のマシン上だけで、外部にデータを送るのはAPI問い合わせに限定される。
防災やアーカイブの勉強会で、検索の「ずれ」そのものを主題にしたかったことからつくった。
なぜこうしたツールを手元でつくるのか
三つのうち二つは、データを外部に送らず、ファイルを開くかビルドした静的ファイルを開くだけで完結する。残る一つも、API経由の問い合わせ以外はローカルで完結している。自分にとっての利点は、次のようなものだ。
- プライバシー:リストや原稿・スライドを、自分の意図しないサーバーに送らないで済む。
- 手元で完結:ネットがなくても、変換や計算の多くはできる(ひなぎくアプリだけはAPIが必要)。
- 改変しやすい:自分用の前提(Obsidian のフォルダ構成、科研費の予算の考え方など)をそのままコードに落とし込める。
一方で、「正式には何と呼ぶか」という問いには、いまだにしっくりする一言がない。静的ウェブアプリと言えば技術者には通じるが、中身が「アプリ」らしい振る舞いをしていることを含意させたいときには、「ローカルで動く(あるいはローカル完結の)ウェブアプリ」と補足するのが、自分にはいちばんわかりやすい。
おわりに
Cursor を使うと、やりたいことの説明と、既存コードの断片から、ここで挙げたような規模のツールを、一人でここまでつくれる、という実感がある。その分、「何ができて何ができないか」「データはどこまでローカルに留まるか」は、自分で確かめながら設計する必要がある。
とはいえ最初からうまくCursorに注文をつけられるわけではなく,ChatGPTでプロンプトを練ってから投げかけるようにしている。
それでも,ひとつのアプリにつきかけた時間は数時間程度だ。これはコードを書けない素人が作ったとしては破格のスピードだろう。
これらを誰かに配布するときは、README に「サーバー不要」「データはブラウザ内のみ」と明示し、必要ならビルド手順や `file://` で開く際の注意(一部環境ではセキュリティ制約で動かない場合があること)も書いておくようにしている。同じように、手元で動く小さなツールをつくっている人にとって、このまとめが少しでも参照になればと思う。
